技术运营的初入指南
什么是技术运营,从字面上来说,就是使用利用技术做服务的人,或者是说直接能操作技术的人。他们不是开发,开发是创造技术的人,他们在工作中,可能是DBA,可能是运维,可能是SA。他们是上层的技术使用人员,他们不编码创造实际的技术,但是他们懂得维护,使用,规划,让技术能够被使用,服务于更上层的设施。随着时代的发展,技术运营也在不断的改变着,可能现在大家说云时代,云原生,技术运营是不是没用了,必然不是,只是技术的升级,让我们面向的技术发生了改变。我们必然要顺应的时代的潮流,构建新时代的技术运营之路。
本文只阐述业务运维的技术运营初入
技术运营之路的发展
谷歌SRE 现代技术运营之路的圣经
谷歌SRE 讲述了谷歌到现在为止,是如何支持谷歌全球系统的模式和方法。让我们知道了在一个复杂系统的公司中,该如何去构建我们的技术运营之路。
谷歌SRE虽然详细的阐述了谷歌在技术运营道路上的探索和实践,但确是大部分公司不太能够复制的。
谷歌SRE有两种人员
- 全职的开发人员
- 一半开发,一半负责运营事务的人员
也就是说要构建和谷歌一样的技术运营体系,我们需要将现有的运维人员体系升级,改头换面。这需要付出比较大的成本。特别是中国国内公司大部分的技术运营部门,主要以运营事务为主,基本没有成体系的开发能力。难以构建出类似的SRE体系。
为什么我们讲技术运营而不是技术运维
两者的区别关键
| 运营 | 运维 |
|---|---|
| 主动的 | 被动的 |
| 长期可持续的 | 短期不可持续 |
| 积极前进 | 稳定固守 |
| 改进 | 维护 |
长期以来,传统运维一直有着右边的缺陷,因为大部分的运维部门一直是执行的角色,很难有主观性,
- 按操作手册执行
- 不出事就行
- 固步自封
- 更新迭代缓慢
长期的刻板印象,导致大部分人对这一领域存在偏见。
但是其实从谷歌SRE的输出来看,技术运营其实是公司长效运营的重要支撑领域, 我们可以更好的维护系统,以及如何做到更加稳定更加高效的持续运营之路。
所以我们更应该转换我们的思维方式,发挥我们的长处。从被动向主动,更加积极的从业务出发,发展迭代处于自己的技术运营之路。
- 贴近业务
- 宏观上的了解
- 底层上的领悟
运维的时代挑战
每个时代都有各自时代的挑战。
物理机时代
其实我们的一开始的运维人员都是直接面对机器,操作的机器都是实体机器而去都是物理机器的时代,我们面临的就是
- 利用率不高
- 难以合理自动化
- 机型差异大
- 需要关注硬件状态
虚拟机时代
随着时代的发展,我们已经意识到物理机的缺陷,所以开始发展出了虚拟化技术,即一台物理机器可以运行多个操作系统,而且能够共享资源。这样就带来了
- 利用率开始提高
- 需要关注不同虚拟化的差异
云计算时代
云计算时代的目标,就是将我们的计算和存储做到按需使用,即水和电一样,用到多少,付费多少。单其实一开始的云计算目标,也还是我们虚拟化技术的发展导致的,我们将单机的虚拟化技术升级到集群,机房级别的虚拟机调度,创建,共享。
- 按需使用
- 云上共享资源的问题
- 潜在的性能问题
云原生时代
在云原生的时代,关注已经从机器资源脱离,我们需要面对更加抽象的目标 计算,存储,应用,发布模式也随着转变
- 不在面向机器运维
- 面向更加抽象的目标 应用 容器 serverless等
- 声明式描述
- 不可变基础设施
技术运营(运维)之路的发展方向
本章我们将阐述,技术运营在未来的发展方向。
持续交付&持续部署(CD)
这些工作其实一直是我们的核心工作,我们一般的流程就是开发构建交付产物之后,我们能够高效快速的部署到服务器上面。
基于虚拟机&物理机
基于虚机的交付方式,一般要求我们的构建产物为可执行的实际二进制等。我们需要将对应的产物分发到我们的目标机器上。然后进行批量的启动,reload, 或者重启等操作。或者就是向我们的目标客户交付我们包装过的安装包等。
我们需要面对的是
- 产物分发
- 配置管理以及下发
- 更新方式
- 进程管控
- 版本管理
- 流量控制
云原生时代的交付
云原生的交付,一般交付的产物就是容器镜像,以及对应的声明式配置。
- 需要规范镜像tag的版本交付
- 云原生的发布方式
DEVOPS
DEVOPS是现在非常火的一个概念
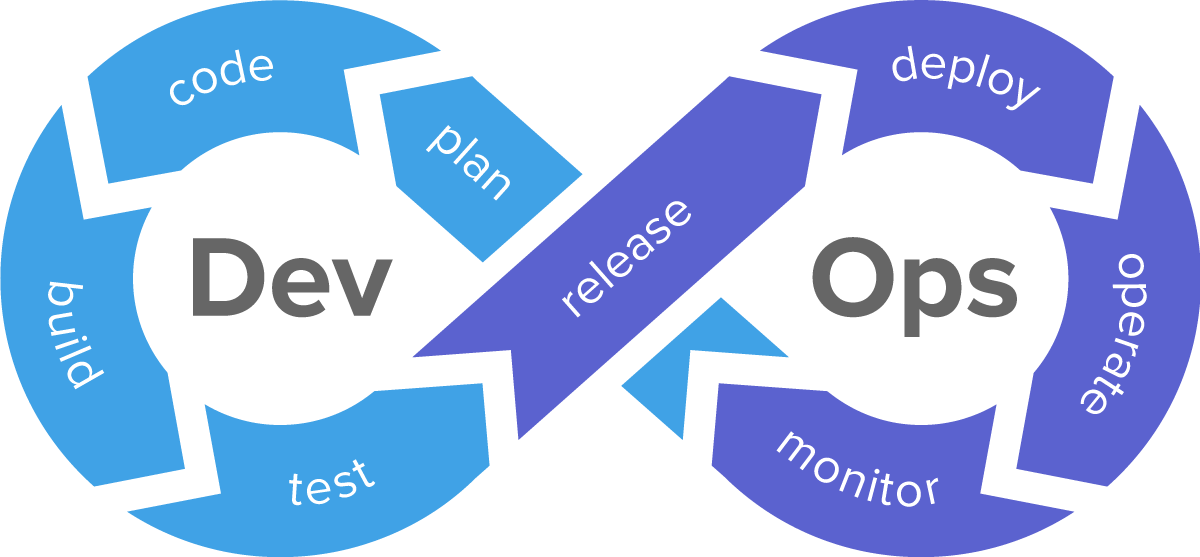
以及上述我们所讲的谷歌SRE体系其实就是devops在谷歌的实践之路
但是我们其实对DEVOPS一体化存在许多的理解
DEVOPS左移
开发开始负责运维的工作,即团队内不存在运维,其实就是我们需要构建一个一体化的发布流程。我们只需要简单的推送代码,构建,灰度,点击发布,就ok,不在需要关注实际的机器。这个只存在于基础完全标准话的公司,有着标准的体系。
DEVOPS右移
即运维开始开发,运维开始开发,就是做一些辅助性的系统,或者是工具,即我们在脱离繁琐的体力工作之后,我们就可以极高的提高沉淀我们的生产力
- 作业系统
- 发布系统
- 代码检查
- 流程系统
- 等
但是运维做开发,有一个前提,就是我们需要一个完善的paas平台帮助运维去快速构建应用系统,减轻心智负担,才能很好的做到运维向开发的转型。
海量自动化
海量自动化,其实该如何理解,其实就是我们拥有将工作当初所遇到繁琐,体力性的工作转变为自动化的能力,这是我们技术运营的核心能力之一。其实在AWS每年都有要求提高多少自动化的指标。
- 不需要人的地方,机器完成
- 需要人的地方,用机器辅助人完成
我们自动化的目标遵循以上原则。
不管我们面对什么样的流程,或者是工作形式,只要你能快速的去构建自动化的能力,那你就是非常流弊的存在。
AI&DATA OPS
我们运维人员,相对于其他的岗位来说,其实我们是非常贴近业务的,我们知道业务的核心指标,核心数据,而且我们又比数据分析人员,更加的懂相关的技术,所以我们能够去分析业务上的问题,给业务作出参考。
AIOPS
AIOPS是现在技术运营领域一大挑战,随着我们数据和基础的沉淀,我们可以利用相依的AI能力辅助我们的运营之路。
- 智能监控
- 根因分析
- 指标异常检测
- 日志聚类
- 智能预测
- 知识图谱
但是AIOPS对于我们的技术运营人员来说,存在着门槛过高,难以落地的问题。
DATA OPS
数据运营,意味着我们需要从数据的场面出发,去探索数据当中存在的价值,实现要求的是我们的技术运营同学,需要很输入的了解业务,知道哪些数据是有价值的,然后提炼出来,在借助企业的数据平台的能力,输出沉淀到对应的可视化平台。需要学习相应的数据分析和大数据使用相关的能力。
运营规划
运营规划其实是一个比较资深的发展方向,往这个方向发展,其实是需要你在这个领域长期不断的专研。
- 运营流程规划
- 运营标准规划
- 基础运营平台规划
- 基础成本核算
- 项目管理
云原生时代的技术运营挑战
时代不断的发展,我们已经来到云原生时代的发展。我们的基础设施已经高度的抽象,我们技术架构,运行架构也必须适应这个时代发展。
为什么上云
上云的优势,已经很多文章都列举了,这里不在论述。这里我们需要关注的就是我们技术运营需要关注的为什么上云。
- 成本上的考虑
- 不必要的裁撤成本
- paas化的平台体系
- 弹性的资源
- 开箱可用
我们需要学习什么
- 容器操作和管理
- K8s知识
- 微服务理论基础知识
- 网络方案的选型
- 服务治理方案
- 持续交付理论及开发团队的工作流程,研发效能度量方法论
我们在云原生上面可以做什么
发布模式的转变
我们从面向虚拟机的发布模式,需要转变为面相容器,面向应用的发布模式
- 不在关注机器
- 不关注底层配置
- 只关注抽象资源
- 产物发生改变
- 更加的版本化
可观测性建设
可观测性三架马车
- 日志
- 指标
- 分布式跟踪
由于云原生时代,我们的关注点发生改变,我们不在上以前那种直接观察机器,机器上的二进制的方式,我们构建需要在云原生的可观测性方式。